Membangun AI Assistant dengan LLM Lokal: dari Phi 3B ke Qwen 7B
Awalnya cuma iseng. Penasaran gimana cara kerja AI Assistant kayak ChatGPT — dari sisi teknis, bukan cuma make-nya. Gimana caranya sistem bisa stream jawaban kata per kata, gimana konteks percakapan dipertahankan, gimana user/auth dikelola. Daripada baca teori melulu, aku mutusin buat bikin sendiri. Dari nol.
Disclaimer: Aku bukan background IT murni. SMK Teknik Elektro, S1 Sistem Komputer, kerja di dunia Digital dan Freelance. Python? Baru belajar. Tapi arsitektur dan logika sistem — itu yang selalu aku kejar.
Dimulai dari Model Kecil: Phi 2 / 3B
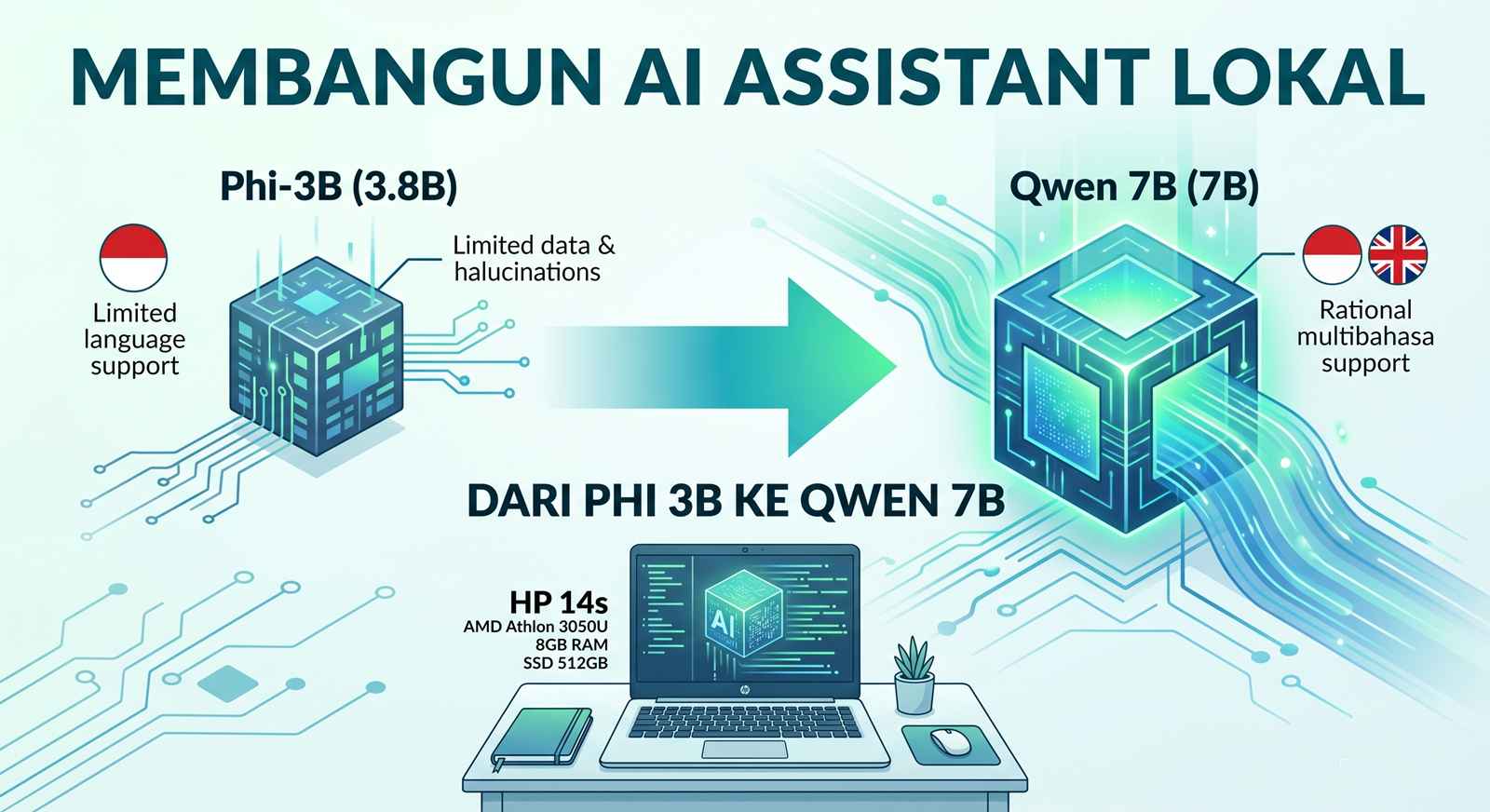
Eksperimen pertama pakai Phi-3 Mini (3.8B) dari Microsoft. Model kecil, cocok buat laptop dengan spek pas-pasan. Hasilnya? Lumayan — untuk knowledge general berbahasa Inggris dia cukup oke, bisa mendefinisikan konsep dengan baik. Tapi begitu disuruh njelasin dalam bahasa Indonesia, mulai ngawur. Hallusinasi tinggi, konteks melenceng, jawaban nggak nyambung.
Saat itu aku paham: model kecil nggak cukup buat bilingual yang decent. Harus naik kelas.

Naik ke 7B / 8B: Spek Laptop Jadi Batu Ujian
Laptop yang dipake cuma HP 14s-fq0562au — AMD Athlon 3050U, 8GB RAM, SSD 512GB. Spesifikasi ini jelas bukan buat main LLM. Tapi aku nekat coba beberapa model 7B dan 8B:
| Model | Parameter | Hasil |
|---|---|---|
| Phi-3 Mini | 3.8B | Kecil, cepat, tapi bahasa Indonesia kacau |
| Llama 3 8B | 8B | Hasilnya cukup lumayan, tapi menurutku Qwen 2.5 Coder 7B lebih natural dan ringan. |
| Qwen 2.5 Coder 7B | 7B | Paling stabil. Indonesia & Inggris rasional. Cocok untuk RAM 8GB. |
Llama 3 8B jelas terlalu lumayan berat — prompt eval bisa 358 detik untuk 1274 token, RAM hampir 8GB. Semua space RAM kepakai, kebayang sendiri. Qwen 2.5 Coder 7B (4-bit quantized) jadi pilihan terakhir yang bertahan sampai sekarang. Ukuran file ~4.5GB, RAM usage ~5GB (masih muat dengan 8GB RAM + swap SSD), dan yang paling penting: jawabannya rasional untuk Indonesia maupun Inggris.
Arsitektur yang Dibangun
Dari rasa penasaran bagaimana aplikasi semacam OpenWeb UI bekerja dan aplikasi chatbot seperti gemini, grok, deepseek, claude dan lainnya, jadilah arsitektur lengkap yang sekarang berjalan di ai.adammuiz.com:
1. LLM Server (llama.cpp)
llama-server dijalankan sebagai systemd service di port 8080. Model GGUF (Q4_K_M) di-load dengan context window 2048 token. Semua request AI lewat sini — inferensi murni di CPU, nggak pake GPU. Bantu doanya juragan 🤲 semoga bisa kebeli VGA RTX 5090 TI 24GB VRAM 🙇♂️ aamiin ...
2. Backend Python (FastAPI + SSE Streaming)
Awalnya ragu karena nggak familiar Python, tapi setelah ngulik beberapa hari, arsitektur mulai terbentuk:
- FastAPI — serving REST API + Jinja2 template buat UI
- SSE (Server-Sent Events) — stream jawaban AI token per token ke frontend, real-time
- httpx async client — komunikasi ke llama-server, timeout panjang (600s) karena inferensi CPU lambat
3. Prompt Builder dengan Priority Context
Batu sandungan pertama: gimana caranya AI ingat chat sebelumnya? Context window cuma 2048 token, nggak muat buat seluruh percakapan. Solusiku adalah priority-based exchange selection:
- User messages selalu disertakan (compact, ~15 token per pesan)
- Assistant responses disertakan selektif — head (topik awal), last (konteks terakhir), dan topic-matched (misal diskusi kode JS)
- Menggunakan template Jinja untuk format chat — biasaku tentuin mana yang jadi
user, mana yangassistant, dan sistem prompt-nya
"Kirimkan kode JS nya saja yang baru saja kamu buat" — tanpa assistant responses, AI nggak tau kode JS mana yang dimaksud. Dengan priority context yang menyertakan respons asisten untuk topik kode, barulah AI bisa menjawab dengan tepat. Ini bedanya engineering: bukan cuma nulis kode, tapi mendesain bagaimana informasi mengalir.

4. Sistem Memori: Dari Full Memory ke Memoryless
Awalnya aku bikin sistem memori penuh — semua chat sebelumnya disimpan dan dikirim sebagai konteks. Tapi karena laptop keberatan, akhirnya aku bikin branch memoryless. Pendekatannya:
- Nggak ada kirim semua riwayat ke AI
- Tapi user bisa mereferensi pesan sebelumnya pakai @ref
- Contoh: ketik
@3 tolong jelaskan kode itu— AI akan lihat konteks dari pesan nomor 3 dan menjawab sesuai - @ref ini jadi jembatan konteks tanpa perlu full memory — efisien, cepat, dan lebih terkontrol
5. Riwayat Chat di MySQL + Management via phpMyAdmin
Setiap percakapan dan pesan disimpan di database MySQL. Dengan per-sequence ID (@1, @2, @3) per percakapan. Buatku, ngelola database lewat phpMyAdmin (GUI browser) itu jauh lebih nyaman daripada terminal. Lihat struktur tabel, query langsung, debug data — semua dari browser.
6. Auth: User & Session di Database
AI Assistant ini punya sistem auth sendiri — user register, login, logout, session token disimpan di database. Password di-hash pakai PBKDF2-SHA256, session pake HttpOnly cookie dengan expiry 7 hari. Nggak semua orang bisa akses — harus punya akun dan di-approve admin. Buat sistem personal kayak gini, kontrol akses itu penting banget.

7. Admin Dashboard
Biar nggak ribet gonta-ganti konfigurasi lewat file, aku bikin dashboard admin yang nyatu sama CMS. Beberapa hal yang dulu hardcode sekarang bisa diatur lewat UI:
- Web Settings — title, header, favicon, AI avatar
- User Management — edit, approve, ubah role
- Model Switching — ganti model LLM, restart service otomatis (cuma role admin). Iya, bisa run multi model, tapi ya sesuaikan juga dengan device home servernya
- File-based Cache — config model disimpan di file
active_model.txt, server nggak perlu query DB tiap kali cek model aktif
8. UX Flow: Percakapan Baru, Switch saat Streaming
Satu hal yang mikirin banget: gimana flow user dari buka app sampai selesai chat?
- Percakapan Baru — tombol di sidebar, langsung bikin session baru. Riwayat sebelumnya tetap tersimpan.
- Switch saat streaming — kalau user ganti percakapan pas AI lagi nulis, stream di-stop, state disimpan. User bisa balik lagi nanti dan lihat progress terakhir. Nggak ada data hilang.
- Confirm sebelum hapus — modal konfirmasi biar nggak salah klik. Dua kali klik baru beneran kehapus.
- Tetap bisa akses percakapan lama — karena semua di database, percakapan bulan lalu masih bisa dibuka, di-cari, di-
@ref.
9. UI Minimal: Alpine.js ala OpenWeb UI
Buat frontend, aku pengen yang minimal, ringan, nggak pake framework berat. Inspirasinya dari OpenWeb UI — clean, dark/light toggle, responsive. Bedanya, aku pake Alpine.js 3.x (CDN), tanpa Node.js build step. Reactive store buat state chat, streaming, auth, dan theme — semuanya diatur lewat x-data dan x-for.
- Typewriter effect — teks muncul karakter per karakter dari buffer, bukan semua sekaligus. Biar lebih natural.
- Loading status — 5s "Thinking…", 15s "Understanding context…", 30s "Retrieving memory…" — user tahu AI sedang proses, bukan hang.
- Dark/light toggle — persist ke localStorage, langsung berubah tanpa reload.
- Mobile responsive — sidebar overlay, safe-area-inset, breakpoint 420px.
Engineering bukan Programmer
Dari project ini, satu hal yang makin kurasain: banyak orang di Indonesia belum paham bedanya engineering dan programming.

Programmer fokus ke syntax — nulis kode yang jalan, ngikutin tutorial, bikin fungsi sesuai instruksi. Engineering? Itu soal arsitektur. Gimana data mengalir, gimana sistem diskalakan, gimana komponen saling komunikasi, gimana error ditangani, gimana keamanan dijaga.
Di project AI ini, syntax Python-ku masih mentah. Tapi arsitekturnya — dari LLM server, ke API streaming, ke frontend real-time, ke database, ke auth — semua aku desain sendiri. Syntax bisa dibantu AI. Sekarang aku pake AI buat nulis fungsi repetitif, debug error, atau generate boilerplate. Tapi logika arsitektur tetap ada di tangan kita.
Engineering = mendesain sistem. Programmer = menulis kode. Keduanya penting, tapi jangan samakan. Project ini bukti bahwa dengan pemahaman arsitektur yang kuat, kita bisa bangun sistem kompleks meskipun baru belajar bahasa pemrogramannya.
Hasil Akhir
Awalnya cuma pengen tahu cara kerja AI Assistant. Sekarang? Selesai dengan arsitektur yang cukup proper:
- LLM Lokal (Qwen 7B) jalan 24/7 di CPU
- Streaming real-time dari FastAPI ke Alpine.js
- Priority context builder yang efisien
- @ref system sebagai jembatan konteks
- Auth + session + admin dashboard
- Setting via database + file cache
- Semua dijalankan dari laptop bekas dengan koneksi SIM Card

Puas? Banget. Bukan karena project-nya sempurna, tapi karena perjalanan belajarnya. Dari nggak bisa Python, nggak ngerti LLM, ragu sama spek laptop — sekarang punya AI sendiri yang jalan di rumah. Semua dari rasa penasaran yang sederhana: "Gimana sih cara kerja AI Assistant?"
Next Plan Engineering: Hybrid = History + Memoryless
Dari yang udah jalan sekarang, aku mulai mikir: gimana caranya dapetin yang terbaik dari dua dunia? Full history (memory) makan banyak token dan bikin LLM kerja berat. Memoryless (@ref) ringan tapi kadang user malas pakai @ref. Apalagi pas lagi ngobrol cepat dan refrensi kontek tidak sengaja diselipkan ke dalam pertanyaan.
Gimana kalau kita hybrid aja? Gabungkan pendekatan history selektif dengan filter konteks di layer sebelum AI.
Ide: Context Filter Layer
Biasanya, semua riwayat percakapan dikirim ke LLM — termasuk referensi kayak "itu", "sebelumnya", "yang tadi kamu bilang". LLM harus mikir sendiri mana konteks yang relevan. Padahal, kata-kata kayak "itu" dan "sebelumnya" itu pola yang bisa dideteksi secara mekanis, tanpa perlu AI.
Di sistem hybrid ini, aku mau bikin Context Filter Layer yang bekerja sebelum prompt sampai ke LLM:
- Deteksi referensi kontekstual — scan input user untuk kata kunci kayak "itu", "sebelumnya", "yang tadi", "seperti yang", dll.
- Resolusi konteks — kalau terdeteksi, filter akan mengambil konteks yang relevan dari riwayat terdekat, tanpa harus kirim semua riwayat ke LLM
- Prompt final — kirim ke LLM cuma: instruksi sistem + input user yang sudah diperkaya konteks +@ref jika ada
Dampaknya? LLM nggak perlu kerja berat mikirin "ini yang sebelumnya yang mana". Filter udah selesaiin itu. Prompt jadi lebih pendek, konteks tetap akurat, token hemat. Dan yang paling penting: AI bisa fokus menjawab, bukan mikir konteks.

Client-side vs Server-side: Mana yang Aman?
Pertanyaan menarik: filter ini dijalanin di mana?
Client-side (JavaScript): Filter jalan di browser user. User ketik "itu, sebelumnya..." — JavaScript deteksi, ambil konteks dari messages yang udah di-load di frontend, kirim hasil filter ke server. Menghemat resource server karena proses parsing nggak perlu pegang CPU server. Tapi risikonya: semua logika filtering terekspos di client. Kode JS bisa dimanipulasi, user bisa bypass filter atau kirim payload aneh langsung ke API. Kalau untuk project personal kayak ai.adammuiz.com yang cuma dipake sendiri, ini bukan masalah besar. Tapi kalau dibuka untuk publik? Server-side filtering tetap wajib sebagai lapisan keamanan tambahan.
Server-side (Python/FastAPI): Filter jalan di backend sebelum prompt dikirim ke llama-server. Aman dari manipulasi client, logika tersembunyi, dan bisa di-audit. Konsekuensinya: resource server dipakai buat parsing tiap request. Tapi karena operasinya ringan (string matching, lookup dictionary) — bukan inferensi LLM — bebannya nggak seberapa. Malah lebih ringan dari pada kirim full history 1000 token ke LLM.
Menurutku, pendekatan ideal adalah hybrid juga di sini: client-side buat initial filter (cepat, real-time feed back ke user kayak "Konteks terdeteksi: @12"), server-side buat final filter & validasi sebelum prompt sampai ke LLM. Jadi client bantu ringanin server, tapi server tetap pegang kendali akhir. Dua lapis, saling nutupin.
Intinya: Context Filter Layer ini bukan cuma soal efisiensi — tapi soal arsitektur percakapan yang lebih cerdas. Alih-alih kirim semua konteks mentah ke LLM, kita saring dulu. LLM dapet input yang bersih, fokus, dan relevan. Ini engineering: mendesain bagaimana informasi mengalir, bukan cuma nulis kode.
